huggingface/transformers
huggingface/transformers
Activity
Last release
Open issues
Open PRs
License
release notes
release notes
Published 8/29/2025
MinorContains breaking changesDINOv3 is a family of versatile vision foundation models that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models.
You can find all the original DINOv3 checkpoints under the DINOv3 collection.
he X-Codec model was proposed in Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model by Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, Wei Xue
The X-Codec model is a neural audio codec that integrates semantic information from self-supervised models (e.g., HuBERT) alongside traditional acoustic information. This enables :
The Ovis2 is an updated version of the Ovis model developed by the AIDC-AI team at Alibaba International Digital Commerce Group.
Ovis2 is the latest advancement in multi-modal large language models (MLLMs), succeeding Ovis1.6. It retains the architectural design of the Ovis series, which focuses on aligning visual and textual embeddings, and introduces major improvements in data curation and training methods.
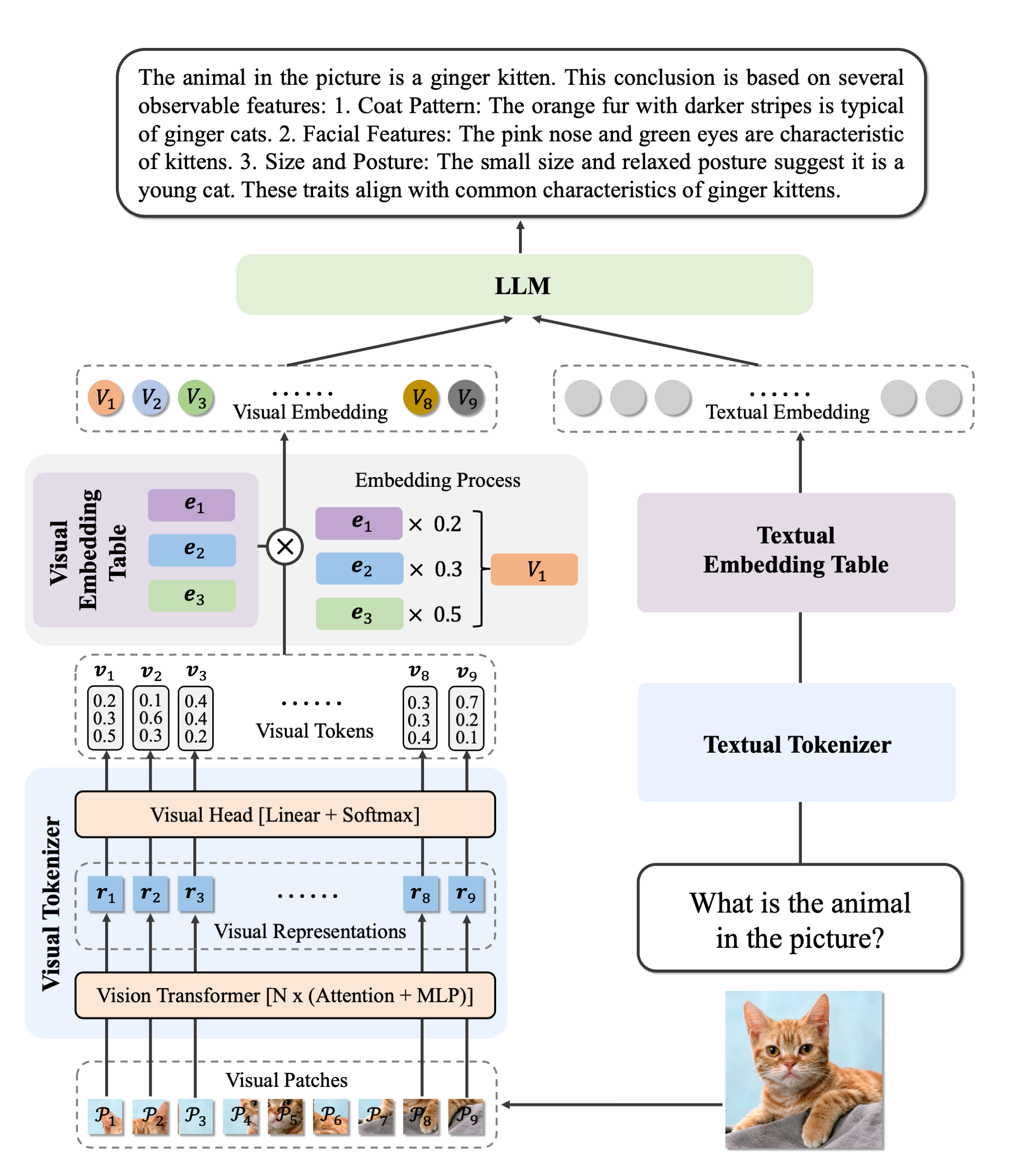
MetaCLIP 2 is a replication of the original CLIP model trained on 300+ languages. It achieves state-of-the-art (SOTA) results on multilingual benchmarks (e.g., XM3600, CVQA, Babel‑ImageNet), surpassing previous SOTA such as mSigLIP and SigLIP‑2. The authors show that English and non-English worlds can mutually benefit and elevate each other.
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages the FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.
SAM2 (Segment Anything Model 2) was proposed in Segment Anything in Images and Videos by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer.
The model can be used to predict segmentation masks of any object of interest given an input image or video, and input points or bounding boxes.
The Kosmos-2.5 model was proposed in KOSMOS-2.5: A Multimodal Literate Model by Microsoft.
The abstract from the paper is the following:
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.

More information at release 🤗
More information at release 🤗
More information at release 🤗
Beyond a large refactor of the caching system in Transformers, making it much more practical and general, models using sliding window attention/chunk attention do not waste memory anymore when caching past states. It was allowed most notable by:
See the following improvements on memory usage for Mistral (using only sliding layers) and GPT-OSS (1 out of 2 layers is sliding) respectively:
Beyond memory usage, it will also improve generation/forward speed by a large margin for large contexts, as only necessary states are passed to the attention computation, which is very sensitive to the sequence length.
Since the GPT-OSS release which introduced the MXPF4 quantization type, several improvements have been made to the support, which should now stabilize.
swiglu_limit not passed in for MXFP4 by @danielhanchen in #40197Mxfp4] Add a way to save with a quantization method by @ArthurZucker in #40176Now that we deprecated tensorflow and jax, we felt that torch_dtype was not only misaligned with torch, but was redundant and hard to remember. For this reason, we switched to a much more standard dtype argument!
torch_dtype will still be a valid usage for as long as needed to ensure a smooth transition, but new code should use dtype, and we encourage you to update older code as well!
The following commits are breaking changes in workflows that were either buggy or not working as expected.
On models where the hub checkpoint specifies cache_implementation="hybrid" (static sliding window hybrid cache), UNSETS this value. This will make the model use the dynamic sliding window layers by default.
This default meant that there were widespread super slow 1st generate calls on models with hybrid caches, which should nol onger be the case.
Cache the computation of sine positional embeddings for MaskFormer; results in a 6% performance improvement.
Adds explicit cache initialization to prepare for the deprecation of the from_legacy_cache utility.
fullgraph=FalseHaving fullgraph set to True during compilation ended up being very restrictive, especially with the arrival of widely-used MoEs.
The DoLa decoding strategy has been moved to the following remote-code repository a few versions ago: https://huggingface.co/transformers-community/dola
The Contrastive Search decoding strategy has been moved to the following remote-code repository a few versions ago: https://huggingface.co/transformers-community/contrastive-search
Both have now been removed from the library as a result.
Flash attention has used sliding window sizes which were off by one. This affected generations that had initially bigger contexts than the sliding window size.
Torch 2.1 support has been unreliable for some time, so we've now made it official and bumped our minimum version to 2.2.
GptOss fixes for green CI by @gante in #39929utils/check_bad_commit.py failing due to rate limit (requesting api.github.com) by @ydshieh in #39918torch.device('cpu').index being None by @manueldeprada in #39933torchcodec is updated by @ydshieh in #39951triton_kernels dep with kernels instead by @SunMarc in #39926fix_and_overwrite mode of utils/check_docstring.py by @manueldeprada in #39369find_file_type by @yonigozlan in #39897past_key_value to past_key_valueS everywhere by @Cyrilvallez in #39956notification_service.py about time_spent by @ydshieh in #40037notification_service.py about time_spent" by @ydshieh in #40044torchcodec==0.5.0 and use torch 2.8 on daily CI by @ydshieh in #40072time_spent in notification_service.py. by @ydshieh in #40081GPT Big Code] Fix attention scaling by @vasqu in #40041ForConditionalGeneration by @qgallouedec in #39973is_fast to ImageProcessor by @MilkClouds in #39603logger.warning with logger.warning_once in GradientCheckpointingLayer by @qgallouedec in #40091Flash Attention] Fix flash attention integration by @vasqu in #40002custom_generate collections by @gante in #39894tiny_agents.md to Korean by @AhnJoonSung in #39913content inputs for LLMs by @gante in #39829decoding_method argument in generate by @manueldeprada in #40085generation_config by @gante in #40127main_classes/processors.md to Korean by @TaskerJang in #39519jamba.md to Korean by @skwh54 in #39890main_classes/optimizer_schedules.md to Korean by @luckyvickyricky in #39713gpt2.md to Korean by @taemincode in #39808optimizers.md to Korean by @chelsseeey in #40011pipelines.md to Korean by @xhaktm00 in #39577gemma3.md to Korean by @seopp in #39865torch_compile_test and torch_export_test by @ydshieh in #39950self.tokenizer by self.processing_class by @qgallouedec in #40119too long with no output by @ydshieh in #40201model_input_names for PixtralImageProcessor by @rohitrango in #40226chat_template (jinja2) as an extra dependency by @tboerstad in #40128CI] Fix repo consistency by @vasqu in #40249k_proj weight and bias slicing in D-FINE by @notkisk in #40257id=usage to <hfoptions> tag in LayoutLM model card by @Jin-HoMLee in #40273torch.compile tests with fullgraph=True by @ydshieh in #40164FA] Fix dtype in varlen with position ids by @vasqu in #40295fix] Pass adamw optimizer parameters to StableAdamW by @emapco in #40184find_executable_batch_size to match new 0.9 ratio by @MilkClouds in #40206Flash Attention] Fix sliding window size by @vasqu in #40163_tp_plan attribute by @rishub-tamirisa in #39944natten by @ydshieh in #40287GPT OSS] Refactor the tests as it was not properly checking the outputs by @ArthurZucker in #40288get_placeholder_mask in Ovis2 by @thisisiron in #40280/en/model_doc by @gante in #40311/en/model_doc by @gante in #40344test_spm_converter_bytefallback_warning by @ydshieh in #40284FA] Fix some model tests by @vasqu in #40350label_names as an argument to TrainingArguments by @huzaifa-jawad367 in #40353skip_special_tokens in the main text generation pipelines by @gante in #40356dtype instead of torch_dtype everywhere! by @Cyrilvallez in #39782tokenizer_kwargs argument to the text generation pipeline by @Joshua-Chin in #40364transformers TF classes/methods by @gante in #40429models.md to Korean by @Judy-Choi in #39518main by @ydshieh in #40451qwen2_moe tests by @ydshieh in #40494merge to main by @ydshieh in #40503The following contributors have made significant changes to the library over the last release:
release notes
Published 8/29/2025
MinorContains breaking changesDINOv3 is a family of versatile vision foundation models that outperforms the specialized state of the art across a broad range of settings, without fine-tuning. DINOv3 produces high-quality dense features that achieve outstanding performance on various vision tasks, significantly surpassing previous self- and weakly-supervised foundation models.
You can find all the original DINOv3 checkpoints under the DINOv3 collection.
he X-Codec model was proposed in Codec Does Matter: Exploring the Semantic Shortcoming of Codec for Audio Language Model by Zhen Ye, Peiwen Sun, Jiahe Lei, Hongzhan Lin, Xu Tan, Zheqi Dai, Qiuqiang Kong, Jianyi Chen, Jiahao Pan, Qifeng Liu, Yike Guo, Wei Xue
The X-Codec model is a neural audio codec that integrates semantic information from self-supervised models (e.g., HuBERT) alongside traditional acoustic information. This enables :
The Ovis2 is an updated version of the Ovis model developed by the AIDC-AI team at Alibaba International Digital Commerce Group.
Ovis2 is the latest advancement in multi-modal large language models (MLLMs), succeeding Ovis1.6. It retains the architectural design of the Ovis series, which focuses on aligning visual and textual embeddings, and introduces major improvements in data curation and training methods.
MetaCLIP 2 is a replication of the original CLIP model trained on 300+ languages. It achieves state-of-the-art (SOTA) results on multilingual benchmarks (e.g., XM3600, CVQA, Babel‑ImageNet), surpassing previous SOTA such as mSigLIP and SigLIP‑2. The authors show that English and non-English worlds can mutually benefit and elevate each other.
Florence-2 is an advanced vision foundation model that uses a prompt-based approach to handle a wide range of vision and vision-language tasks. Florence-2 can interpret simple text prompts to perform tasks like captioning, object detection, and segmentation. It leverages the FLD-5B dataset, containing 5.4 billion annotations across 126 million images, to master multi-task learning. The model's sequence-to-sequence architecture enables it to excel in both zero-shot and fine-tuned settings, proving to be a competitive vision foundation model.
SAM2 (Segment Anything Model 2) was proposed in Segment Anything in Images and Videos by Nikhila Ravi, Valentin Gabeur, Yuan-Ting Hu, Ronghang Hu, Chaitanya Ryali, Tengyu Ma, Haitham Khedr, Roman Rädle, Chloe Rolland, Laura Gustafson, Eric Mintun, Junting Pan, Kalyan Vasudev Alwala, Nicolas Carion, Chao-Yuan Wu, Ross Girshick, Piotr Dollár, Christoph Feichtenhofer.
The model can be used to predict segmentation masks of any object of interest given an input image or video, and input points or bounding boxes.
The Kosmos-2.5 model was proposed in KOSMOS-2.5: A Multimodal Literate Model by Microsoft.
The abstract from the paper is the following:
We present Kosmos-2.5, a multimodal literate model for machine reading of text-intensive images. Pre-trained on large-scale text-intensive images, Kosmos-2.5 excels in two distinct yet cooperative transcription tasks: (1) generating spatially-aware text blocks, where each block of text is assigned its spatial coordinates within the image, and (2) producing structured text output that captures styles and structures into the markdown format. This unified multimodal literate capability is achieved through a shared Transformer architecture, task-specific prompts, and flexible text representations. We evaluate Kosmos-2.5 on end-to-end document-level text recognition and image-to-markdown text generation. Furthermore, the model can be readily adapted for any text-intensive image understanding task with different prompts through supervised fine-tuning, making it a general-purpose tool for real-world applications involving text-rich images. This work also paves the way for the future scaling of multimodal large language models.
More information at release 🤗
More information at release 🤗
More information at release 🤗
Beyond a large refactor of the caching system in Transformers, making it much more practical and general, models using sliding window attention/chunk attention do not waste memory anymore when caching past states. It was allowed most notable by:
See the following improvements on memory usage for Mistral (using only sliding layers) and GPT-OSS (1 out of 2 layers is sliding) respectively:
Beyond memory usage, it will also improve generation/forward speed by a large margin for large contexts, as only necessary states are passed to the attention computation, which is very sensitive to the sequence length.
Since the GPT-OSS release which introduced the MXPF4 quantization type, several improvements have been made to the support, which should now stabilize.
swiglu_limit not passed in for MXFP4 by @danielhanchen in #40197Mxfp4] Add a way to save with a quantization method by @ArthurZucker in #40176Now that we deprecated tensorflow and jax, we felt that torch_dtype was not only misaligned with torch, but was redundant and hard to remember. For this reason, we switched to a much more standard dtype argument!
torch_dtype will still be a valid usage for as long as needed to ensure a smooth transition, but new code should use dtype, and we encourage you to update older code as well!
The following commits are breaking changes in workflows that were either buggy or not working as expected.
On models where the hub checkpoint specifies cache_implementation="hybrid" (static sliding window hybrid cache), UNSETS this value. This will make the model use the dynamic sliding window layers by default.
This default meant that there were widespread super slow 1st generate calls on models with hybrid caches, which should nol onger be the case.
Cache the computation of sine positional embeddings for MaskFormer; results in a 6% performance improvement.
Adds explicit cache initialization to prepare for the deprecation of the from_legacy_cache utility.
fullgraph=FalseHaving fullgraph set to True during compilation ended up being very restrictive, especially with the arrival of widely-used MoEs.
The DoLa decoding strategy has been moved to the following remote-code repository a few versions ago: https://huggingface.co/transformers-community/dola
The Contrastive Search decoding strategy has been moved to the following remote-code repository a few versions ago: https://huggingface.co/transformers-community/contrastive-search
Both have now been removed from the library as a result.
Flash attention has used sliding window sizes which were off by one. This affected generations that had initially bigger contexts than the sliding window size.
Torch 2.1 support has been unreliable for some time, so we've now made it official and bumped our minimum version to 2.2.
GptOss fixes for green CI by @gante in #39929utils/check_bad_commit.py failing due to rate limit (requesting api.github.com) by @ydshieh in #39918torch.device('cpu').index being None by @manueldeprada in #39933torchcodec is updated by @ydshieh in #39951triton_kernels dep with kernels instead by @SunMarc in #39926fix_and_overwrite mode of utils/check_docstring.py by @manueldeprada in #39369find_file_type by @yonigozlan in #39897past_key_value to past_key_valueS everywhere by @Cyrilvallez in #39956notification_service.py about time_spent by @ydshieh in #40037notification_service.py about time_spent" by @ydshieh in #40044torchcodec==0.5.0 and use torch 2.8 on daily CI by @ydshieh in #40072time_spent in notification_service.py. by @ydshieh in #40081GPT Big Code] Fix attention scaling by @vasqu in #40041ForConditionalGeneration by @qgallouedec in #39973is_fast to ImageProcessor by @MilkClouds in #39603logger.warning with logger.warning_once in GradientCheckpointingLayer by @qgallouedec in #40091Flash Attention] Fix flash attention integration by @vasqu in #40002custom_generate collections by @gante in #39894tiny_agents.md to Korean by @AhnJoonSung in #39913content inputs for LLMs by @gante in #39829decoding_method argument in generate by @manueldeprada in #40085generation_config by @gante in #40127main_classes/processors.md to Korean by @TaskerJang in #39519jamba.md to Korean by @skwh54 in #39890main_classes/optimizer_schedules.md to Korean by @luckyvickyricky in #39713gpt2.md to Korean by @taemincode in #39808optimizers.md to Korean by @chelsseeey in #40011pipelines.md to Korean by @xhaktm00 in #39577gemma3.md to Korean by @seopp in #39865torch_compile_test and torch_export_test by @ydshieh in #39950self.tokenizer by self.processing_class by @qgallouedec in #40119too long with no output by @ydshieh in #40201model_input_names for PixtralImageProcessor by @rohitrango in #40226chat_template (jinja2) as an extra dependency by @tboerstad in #40128CI] Fix repo consistency by @vasqu in #40249k_proj weight and bias slicing in D-FINE by @notkisk in #40257id=usage to <hfoptions> tag in LayoutLM model card by @Jin-HoMLee in #40273torch.compile tests with fullgraph=True by @ydshieh in #40164FA] Fix dtype in varlen with position ids by @vasqu in #40295fix] Pass adamw optimizer parameters to StableAdamW by @emapco in #40184find_executable_batch_size to match new 0.9 ratio by @MilkClouds in #40206Flash Attention] Fix sliding window size by @vasqu in #40163_tp_plan attribute by @rishub-tamirisa in #39944natten by @ydshieh in #40287GPT OSS] Refactor the tests as it was not properly checking the outputs by @ArthurZucker in #40288get_placeholder_mask in Ovis2 by @thisisiron in #40280/en/model_doc by @gante in #40311/en/model_doc by @gante in #40344test_spm_converter_bytefallback_warning by @ydshieh in #40284FA] Fix some model tests by @vasqu in #40350label_names as an argument to TrainingArguments by @huzaifa-jawad367 in #40353skip_special_tokens in the main text generation pipelines by @gante in #40356dtype instead of torch_dtype everywhere! by @Cyrilvallez in #39782tokenizer_kwargs argument to the text generation pipeline by @Joshua-Chin in #40364transformers TF classes/methods by @gante in #40429models.md to Korean by @Judy-Choi in #39518main by @ydshieh in #40451qwen2_moe tests by @ydshieh in #40494merge to main by @ydshieh in #40503The following contributors have made significant changes to the library over the last release:
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.