huggingface/transformers
huggingface/transformers
Activity
Last release
Open issues
Open PRs
License
release notes
release notes
Published 3/21/2025
MinorContains breaking changesStarting with version v4.49.0, we have been doing model-based releases, additionally to our traditional, software-based monthly releases. These model-based releases provide a tag from which models may be installed.
Contrarily to our software-releases; these are not pushed to pypi and are kept on our GitHub. Each release has a tag attributed to it, such as:
v4.49.0-Gemma-3v4.49.0-AyaVision⚠️ As bugs are identified and fixed on each model, the release tags are updated so that installing from that tag always gives the best experience possible with that model.
Each new model release will always be based on the current state of the main branch at the time of its creation. This ensures that new models start with the latest features and fixes available.
For example, if two models—Gemma-3 and AyaVision—are released from main, and then a fix for gemma3 is merged, it will look something like this:
o---- v4.49.0-Gemma-3 (includes AyaVision, plus main fixes)
/ \
---o--o--o--o--o-- (fix for gemma3) --o--o--o main
\
o---- v4.49.0-AyaVision
We strive to merge model specific fixes on their respective branches as fast as possible!
Gemma 3 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The Gemma 3 model was proposed by Google. It is a vision-language model composed by a SigLIP vision encoder and a Gemma 2 language decoder linked by a multimodal linear projection.
It cuts an image into a fixed number of tokens same way as Siglip if the image does not exceed certain aspect ratio. For images that exceed the given aspect ratio, it crops the image into multiple smaller pacthes and concatenates them with the base image embedding.
One particularity is that the model uses bidirectional attention on all the image tokens. Also, the model interleaves sliding window local attention with full causal attention in the language backbone, where each sixth layer is a full causal attention layer.
ShieldGemma 2 is built on Gemma 3, is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. To train a robust image safety model, we curated training datasets of natural and synthetic images and instruction-tuned Gemma 3 to demonstrate strong performance.
AyaVision is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
Aya Vision 8B combines the Siglip2-so400-384-14 vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
Key features of Aya Vision include:
Mistral 3.1 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
It is ideal for:
SmolVLM-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
SigLIP-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The SigLIP2 model was proposed in SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner and Xiaohua Zhai.
The model comes in two variants
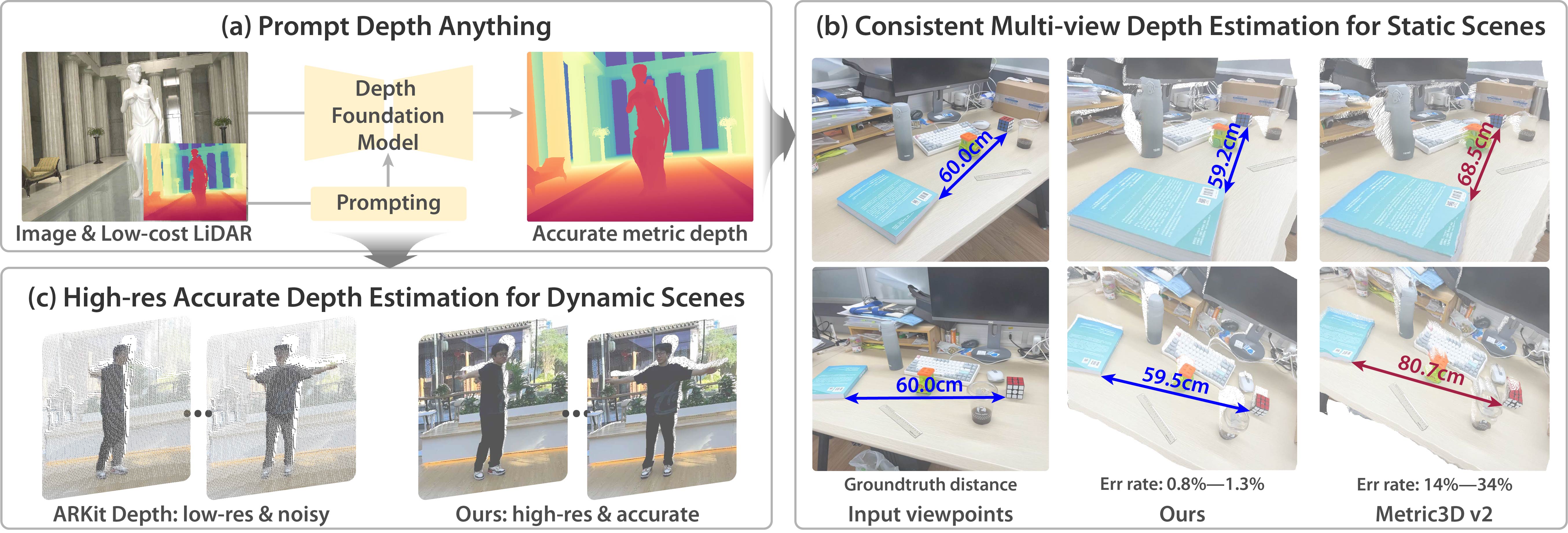
transformers)PromptDepthAnything is a high-resolution, accurate metric depth estimation model that leverages prompting, inspired by its success in vision-language (VLMs) and large language models (LLMs). Using iPhone LiDAR as a prompt, the model generates precise depth maps at up to 4K resolution, unlocking the potential of depth foundation models.
We add a new tool to transformers to visualize the attention layout of a given model. It only requires a model ID as input, and will load the relevant tokenizer/model and display what the attention mask looks like. Some examples:
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("meta-llama/Llama-3.2-3B-Instruct")
visualizer("A normal attention mask")
visualizer = AttentionMaskVisualizer("mistralai/Mistral-Small-24B-Instruct-2501")
visualizer("A normal attention mask with a long text to see how it is displayed, and if it is displayed correctly")
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> You are an assistant.", suffix = "What is on the image?")
visualizer = AttentionMaskVisualizer("google/gemma-2b")
visualizer("You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
visualizer = AttentionMaskVisualizer("google/gemma-3-27b-it")
visualizer("<img>You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
We are deprecating transformers.agents in favour of the smolagents library. Read more about smolagents here.
We support adding custom quantization method by using the [@register](https://github.com/register)_quantization_config and [@register](https://github.com/register)_quantizer decorator:
[@register](https://github.com/register)_quantization_config("custom")
class CustomConfig(QuantizationConfigMixin):
pass
[@register](https://github.com/register)_quantizer("custom")
class CustomQuantizer(HfQuantizer):
pass
quantized_model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
)
AMD is developing its in-house quantizer named Quark released under MIT license, which supports a broad range of quantization pre-processing, algorithms, dtypes and target hardware. You can now load a model quantized by quark library:
# pip install amd-quark
model_id = "EmbeddedLLM/Llama-3.1-8B-Instruct-w_fp8_per_channel_sym"
model = AutoModelForCausalLM.from_pretrained(model_id)
model = model.to("cuda")
Torchao is augmented with autoquant support, CPU-quantization, as well as new AOBaseConfig object instances for more advanced configuration.
At loading time, the parallelization is now applied module-by-module, so that no memory overhead is required compared to what the final weight distribution will be!
This release includes two speed upgrades to generate:
do_sample=True;from transformers import pipeline
import torch
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
pipe = pipeline(
"text-generation",
model=checkpoint,
assistant_model=assistant_checkpoint,
do_sample=True
)
pipe_output = pipe(prompt, max_new_tokens=50, do_sample=True)
print(pipe_output[0]["generated_text"])
num_beams. The speedup is more visible on smaller models, where model.forward doesn't dominate the total run time.CandidateGenerator by @keyboardAnt, @jmamou, and @gauravjain14 in #35029A significant redesign of our documentation has wrapped-up. The goal was to greatly simplify the transformers documentation, making it much more easy to navigate. Let us know what you think!
The research examples folder that was hosted in transformers is no more. We have moved it out of transformers and in the following repo: github.com/huggingface/transformers-research-projects/
We have updated our flex attention support so as to have it be on-par with our Flash Attention 2 support.
EsmModelIntegrationTest::test_inference_bitsandbytes by @faaany in #36225LlavaForConditionalGenerationModelTest::test_config after #36077 by @ydshieh in #36230/generation by @gante in #36235test_export_to_onnx by @gante in #36241test_fast_is_faster_than_slow by @ydshieh in #36240Speech2TextFeatureExtractor API. by @KarelVesely84 in #34638pt_tf equivalence tests by @gante in #36253test_from_pretrained_low_cpu_mem_usage_equal less flaky by @gante in #36255GenerationTesterMixin inheritance is correct 🐛 🔫 by @gante in #36180main by @ydshieh in #36375is_causal fail with compile by @Cyrilvallez in #36374benchmark.yml by @ydshieh in #36402CandidateGenerator by @keyboardAnt in #35029contents: write by @ydshieh in #36445torch.distributed-compatible DynamicCache by @gante in #36373src/transformers/image_utils.py by @hmellor in #36435hub_retry by @ydshieh in #36449TRUST_REMOTE_CODE for RealmRetriever for security by @ydshieh in #36511input_ids passed to PrefixConstrainedLogitsProcessor is zero by @HiDolen in #36489DataCollatorForLanguageModeling by @capemox in #36457HybridCache] disable automatic compilation by @gante in #36620make fix-copies by @gante in #36664from_pretrained by @Cyrilvallez in #36033meta device by @gante in #36543gc.collect() if only 1 shard is used by @gante in #36721test_eager_matches_sdpa_inference by @gante in #36650generation_config, overwrite default values with the model's base generation_config by @gante in #36684TrainingArguments.torch_empty_cache_steps post_init check by @pkuderov in #36734test_eager_matches_sdpa_inference by @gante in #36740is_decoder usage in PretrainedConfig documentation by @d-kleine in #36724tj-actions/changed-files by @ydshieh in #36795dist": "loadfile" for pytest in CircleCI jobs by @ydshieh in #36811Trainer.collator.tokenizer in when Trainer.processing_class is None by @innerNULL in #36552GenerationMixin by @gante in #36605DataCollatorForLanguageModeling by @capemox in #36497.item in get_batch_samples by @regisss in #36861deformable_detr kernel from the Hub by @danieldk in #36853The following contributors have made significant changes to the library over the last release:
CandidateGenerator (#35029)deformable_detr kernel from the Hub (#36853)release notes
Published 3/21/2025
MinorContains breaking changesStarting with version v4.49.0, we have been doing model-based releases, additionally to our traditional, software-based monthly releases. These model-based releases provide a tag from which models may be installed.
Contrarily to our software-releases; these are not pushed to pypi and are kept on our GitHub. Each release has a tag attributed to it, such as:
v4.49.0-Gemma-3v4.49.0-AyaVision⚠️ As bugs are identified and fixed on each model, the release tags are updated so that installing from that tag always gives the best experience possible with that model.
Each new model release will always be based on the current state of the main branch at the time of its creation. This ensures that new models start with the latest features and fixes available.
For example, if two models—Gemma-3 and AyaVision—are released from main, and then a fix for gemma3 is merged, it will look something like this:
o---- v4.49.0-Gemma-3 (includes AyaVision, plus main fixes)
/ \
---o--o--o--o--o-- (fix for gemma3) --o--o--o main
\
o---- v4.49.0-AyaVision
We strive to merge model specific fixes on their respective branches as fast as possible!
Gemma 3 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The Gemma 3 model was proposed by Google. It is a vision-language model composed by a SigLIP vision encoder and a Gemma 2 language decoder linked by a multimodal linear projection.
It cuts an image into a fixed number of tokens same way as Siglip if the image does not exceed certain aspect ratio. For images that exceed the given aspect ratio, it crops the image into multiple smaller pacthes and concatenates them with the base image embedding.
One particularity is that the model uses bidirectional attention on all the image tokens. Also, the model interleaves sliding window local attention with full causal attention in the language backbone, where each sixth layer is a full causal attention layer.
ShieldGemma 2 is built on Gemma 3, is a 4 billion (4B) parameter model that checks the safety of both synthetic and natural images against key categories to help you build robust datasets and models. With this addition to the Gemma family of models, researchers and developers can now easily minimize the risk of harmful content in their models across key areas of harm as defined below:
We recommend using ShieldGemma 2 as an input filter to vision language models, or as an output filter of image generation systems. To train a robust image safety model, we curated training datasets of natural and synthetic images and instruction-tuned Gemma 3 to demonstrate strong performance.
AyaVision is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The Aya Vision 8B and 32B models is a state-of-the-art multilingual multimodal models developed by Cohere For AI. They build on the Aya Expanse recipe to handle both visual and textual information without compromising on the strong multilingual textual performance of the original model.
Aya Vision 8B combines the Siglip2-so400-384-14 vision encoder with the Cohere CommandR-7B language model further post-trained with the Aya Expanse recipe, creating a powerful vision-language model capable of understanding images and generating text across 23 languages. Whereas, Aya Vision 32B uses Aya Expanse 32B as the language model.
Key features of Aya Vision include:
Mistral 3.1 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
Building upon Mistral Small 3 (2501), Mistral Small 3.1 (2503) adds state-of-the-art vision understanding and enhances long context capabilities up to 128k tokens without compromising text performance. With 24 billion parameters, this model achieves top-tier capabilities in both text and vision tasks.
It is ideal for:
SmolVLM-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
SmolVLM2 is an adaptation of the Idefics3 model with two main differences:
SigLIP-2 is heavily referenced in the following model-based release and we recommend reading these if you want all the information relative to that model.
The SigLIP2 model was proposed in SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features by Michael Tschannen, Alexey Gritsenko, Xiao Wang, Muhammad Ferjad Naeem, Ibrahim Alabdulmohsin, Nikhil Parthasarathy, Talfan Evans, Lucas Beyer, Ye Xia, Basil Mustafa, Olivier Hénaff, Jeremiah Harmsen, Andreas Steiner and Xiaohua Zhai.
The model comes in two variants
transformers)PromptDepthAnything is a high-resolution, accurate metric depth estimation model that leverages prompting, inspired by its success in vision-language (VLMs) and large language models (LLMs). Using iPhone LiDAR as a prompt, the model generates precise depth maps at up to 4K resolution, unlocking the potential of depth foundation models.
We add a new tool to transformers to visualize the attention layout of a given model. It only requires a model ID as input, and will load the relevant tokenizer/model and display what the attention mask looks like. Some examples:
from transformers.utils.attention_visualizer import AttentionMaskVisualizer
visualizer = AttentionMaskVisualizer("meta-llama/Llama-3.2-3B-Instruct")
visualizer("A normal attention mask")
visualizer = AttentionMaskVisualizer("mistralai/Mistral-Small-24B-Instruct-2501")
visualizer("A normal attention mask with a long text to see how it is displayed, and if it is displayed correctly")
visualizer = AttentionMaskVisualizer("google/paligemma2-3b-mix-224")
visualizer("<img> You are an assistant.", suffix = "What is on the image?")
visualizer = AttentionMaskVisualizer("google/gemma-2b")
visualizer("You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
visualizer = AttentionMaskVisualizer("google/gemma-3-27b-it")
visualizer("<img>You are an assistant. Make sure you print me") # we should have slidiing on non sliding side by side
We are deprecating transformers.agents in favour of the smolagents library. Read more about smolagents here.
We support adding custom quantization method by using the [@register](https://github.com/register)_quantization_config and [@register](https://github.com/register)_quantizer decorator:
[@register](https://github.com/register)_quantization_config("custom")
class CustomConfig(QuantizationConfigMixin):
pass
[@register](https://github.com/register)_quantizer("custom")
class CustomQuantizer(HfQuantizer):
pass
quantized_model = AutoModelForCausalLM.from_pretrained(
"facebook/opt-350m", quantization_config=CustomConfig(), torch_dtype="auto"
)
AMD is developing its in-house quantizer named Quark released under MIT license, which supports a broad range of quantization pre-processing, algorithms, dtypes and target hardware. You can now load a model quantized by quark library:
# pip install amd-quark
model_id = "EmbeddedLLM/Llama-3.1-8B-Instruct-w_fp8_per_channel_sym"
model = AutoModelForCausalLM.from_pretrained(model_id)
model = model.to("cuda")
Torchao is augmented with autoquant support, CPU-quantization, as well as new AOBaseConfig object instances for more advanced configuration.
At loading time, the parallelization is now applied module-by-module, so that no memory overhead is required compared to what the final weight distribution will be!
This release includes two speed upgrades to generate:
do_sample=True;from transformers import pipeline
import torch
prompt = "Alice and Bob"
checkpoint = "google/gemma-2-9b"
assistant_checkpoint = "double7/vicuna-68m"
pipe = pipeline(
"text-generation",
model=checkpoint,
assistant_model=assistant_checkpoint,
do_sample=True
)
pipe_output = pipe(prompt, max_new_tokens=50, do_sample=True)
print(pipe_output[0]["generated_text"])
num_beams. The speedup is more visible on smaller models, where model.forward doesn't dominate the total run time.CandidateGenerator by @keyboardAnt, @jmamou, and @gauravjain14 in #35029A significant redesign of our documentation has wrapped-up. The goal was to greatly simplify the transformers documentation, making it much more easy to navigate. Let us know what you think!
The research examples folder that was hosted in transformers is no more. We have moved it out of transformers and in the following repo: github.com/huggingface/transformers-research-projects/
We have updated our flex attention support so as to have it be on-par with our Flash Attention 2 support.
EsmModelIntegrationTest::test_inference_bitsandbytes by @faaany in #36225LlavaForConditionalGenerationModelTest::test_config after #36077 by @ydshieh in #36230/generation by @gante in #36235test_export_to_onnx by @gante in #36241test_fast_is_faster_than_slow by @ydshieh in #36240Speech2TextFeatureExtractor API. by @KarelVesely84 in #34638pt_tf equivalence tests by @gante in #36253test_from_pretrained_low_cpu_mem_usage_equal less flaky by @gante in #36255GenerationTesterMixin inheritance is correct 🐛 🔫 by @gante in #36180main by @ydshieh in #36375is_causal fail with compile by @Cyrilvallez in #36374benchmark.yml by @ydshieh in #36402CandidateGenerator by @keyboardAnt in #35029contents: write by @ydshieh in #36445torch.distributed-compatible DynamicCache by @gante in #36373src/transformers/image_utils.py by @hmellor in #36435hub_retry by @ydshieh in #36449TRUST_REMOTE_CODE for RealmRetriever for security by @ydshieh in #36511input_ids passed to PrefixConstrainedLogitsProcessor is zero by @HiDolen in #36489DataCollatorForLanguageModeling by @capemox in #36457HybridCache] disable automatic compilation by @gante in #36620make fix-copies by @gante in #36664from_pretrained by @Cyrilvallez in #36033meta device by @gante in #36543gc.collect() if only 1 shard is used by @gante in #36721test_eager_matches_sdpa_inference by @gante in #36650generation_config, overwrite default values with the model's base generation_config by @gante in #36684TrainingArguments.torch_empty_cache_steps post_init check by @pkuderov in #36734test_eager_matches_sdpa_inference by @gante in #36740is_decoder usage in PretrainedConfig documentation by @d-kleine in #36724tj-actions/changed-files by @ydshieh in #36795dist": "loadfile" for pytest in CircleCI jobs by @ydshieh in #36811Trainer.collator.tokenizer in when Trainer.processing_class is None by @innerNULL in #36552GenerationMixin by @gante in #36605DataCollatorForLanguageModeling by @capemox in #36497.item in get_batch_samples by @regisss in #36861deformable_detr kernel from the Hub by @danieldk in #36853The following contributors have made significant changes to the library over the last release:
CandidateGenerator (#35029)deformable_detr kernel from the Hub (#36853)🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.