huggingface/transformers
huggingface/transformers
Activity
Last release
Open issues
Open PRs
License
release notes
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
release notes
Published 5/17/2024
MinorContains breaking changesrelease notes
Published 5/17/2024
MinorContains breaking changesThe Phi-3 model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
TLDR; Phi-3 introduces new ROPE scaling methods, which seems to scale fairly well! A 3b and a Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
JetMoe-8B is an 8B Mixture-of-Experts (MoE) language model developed by Yikang Shen and MyShell. JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget. To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the ModuleFormer. Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts. Given the input tokens, it activates a subset of its experts to process them. This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models. The training throughput of JetMoe-8B is around 100B tokens per day on a cluster of 96 H100 GPUs with a straightforward 3-way pipeline parallelism strategy.
PaliGemma is a lightweight open vision-language model (VLM) inspired by PaLI-3, and based on open components like the SigLIP vision model and the Gemma language model. PaliGemma takes both images and text as inputs and can answer questions about images with detail and context, meaning that PaliGemma can perform deeper analysis of images and provide useful insights, such as captioning for images and short videos, object detection, and reading text embedded within images.
More than 120 checkpoints are released see the collection here !
Video-LLaVA exhibits remarkable interactive capabilities between images and videos, despite the absence of image-video pairs in the dataset.
💡 Simple baseline, learning united visual representation by alignment before projection With the binding of unified visual representations to the language feature space, we enable an LLM to perform visual reasoning capabilities on both images and videos simultaneously. 🔥 High performance, complementary learning with video and image Extensive experiments demonstrate the complementarity of modalities, showcasing significant superiority when compared to models specifically designed for either images or videos.

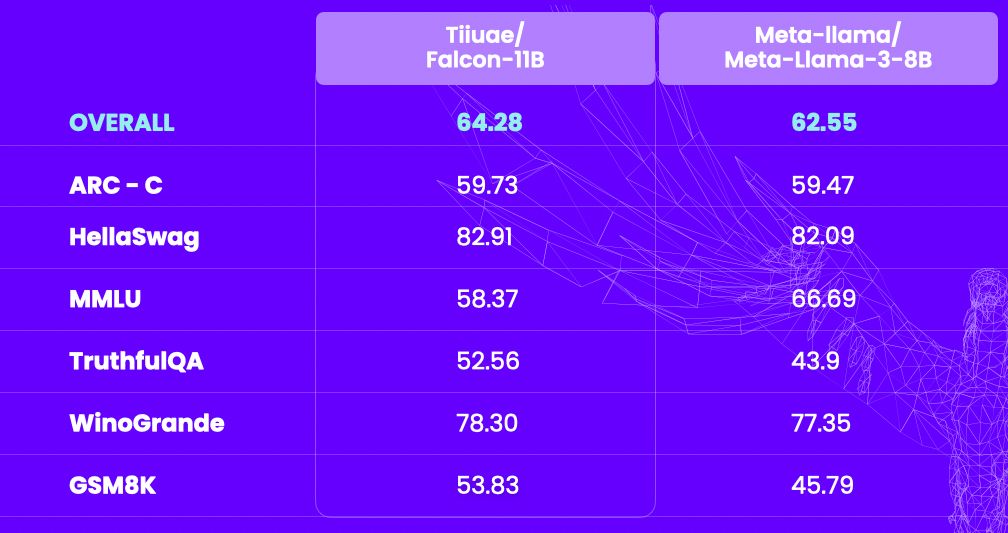
Two new models from TII-UAE! They published a blog-post with more details! Falcon2 introduces parallel mlp, and falcon VLM uses the Llava framework
from_pretrained support
You can now load most of the GGUF quants directly with transformers' from_pretrained to convert it to a classic pytorch model. The API is simple:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
We plan more closer integrations with llama.cpp / GGML ecosystem in the future, see: https://github.com/huggingface/transformers/issues/27712 for more details
v4.41.0 introduces a significant refactor of the Agents framework.
With this release, we allow you to build state-of-the-art agent systems, including the React Code Agent that writes its actions as code in ReAct iterations, following the insights from Wang et al., 2024
Just install with pip install "transformers[agents]". Then you're good to go!
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[])
code = """
list=[0, 1, 2]
for i in range(4):
print(list(i))
"""
corrected_code = agent.run(
"I have some code that creates a bug: please debug it and return the final code",
code=code,
)
In this release we support new quantization methods: HQQ & EETQ contributed by the community. Read more about how to quantize any transformers model using HQQ & EETQ in the dedicated documentation section
dequantize API for bitsandbytes modelsIn case you want to dequantize models that have been loaded with bitsandbytes, this is now possible through the dequantize API (e.g. to merge adapter weights)
dequantize API for bitsandbytes quantized models by @younesbelkada in https://github.com/huggingface/transformers/pull/30806API-wise, you can achieve that with the following:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.dequantize()
text = tokenizer("Hello my name is", return_tensors="pt").to(0)
out = model.generate(**text)
print(tokenizer.decode(out[0]))
min_p sampling by @gante in https://github.com/huggingface/transformers/pull/30639Gemma work with torch.compile by @ydshieh in https://github.com/huggingface/transformers/pull/30775BERT] Add support for sdpa by @hackyon in https://github.com/huggingface/transformers/pull/28802Addition of fine-tuning script for object detection models
Add interpolation of embeddings. This enables predictions from pretrained models on input images of sizes different than those the model was originally trained on. Simply pass interpolate_pos_embedding=True when calling the model.
Added for: BLIP, BLIP 2, InstructBLIP, SigLIP, ViViT
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
image = Image.open(requests.get("https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg", stream=True).raw)
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
).to("cuda")
inputs = processor(images=image, size={"height": 500, "width": 500}, return_tensors="pt").to("cuda")
predictions = model(**inputs, interpolate_pos_encoding=True)
# Generated text: "a woman and dog on the beach"
generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
evaluation_strategy to eval_strategy🚨🚨🚨 by @muellerzr in https://github.com/huggingface/transformers/pull/30190LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881prev_ci_results by @ydshieh in https://github.com/huggingface/transformers/pull/30313pad token id in pipeline forward arguments by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30285jnp import in utils/generic.py by @ydshieh in https://github.com/huggingface/transformers/pull/30322AssertionError in clip conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30321pad_token_id again by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30338Llama family, fix use_cache=False generation by @ArthurZucker in https://github.com/huggingface/transformers/pull/30380-rs to show skip reasons by @ArthurZucker in https://github.com/huggingface/transformers/pull/30318require_torch_sdpa for test that needs sdpa support by @faaany in https://github.com/huggingface/transformers/pull/30408LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881Llava] + CIs fix red cis and llava integration tests by @ArthurZucker in https://github.com/huggingface/transformers/pull/30440paths filter to avoid the chance of being triggered by @ydshieh in https://github.com/huggingface/transformers/pull/30453utils/check_if_new_model_added.py by @ydshieh in https://github.com/huggingface/transformers/pull/30456research_project] Most of the security issues come from this requirement.txt by @ArthurZucker in https://github.com/huggingface/transformers/pull/29977WandbCallback with third parties by @tomaarsen in https://github.com/huggingface/transformers/pull/30477SourceFileLoader.load_module() in dynamic module loading by @XuehaiPan in https://github.com/huggingface/transformers/pull/30370HfQuantizer quant method update by @younesbelkada in https://github.com/huggingface/transformers/pull/30484bitsandbytes error formatting ("Some modules are dispatched on ...") by @kyo-takano in https://github.com/huggingface/transformers/pull/30494dtype_byte_size to handle torch.float8_e4m3fn/float8_e5m2 types by @mgoin in https://github.com/huggingface/transformers/pull/30488DETR] Remove timm hardcoded logic in modeling files by @amyeroberts in https://github.com/huggingface/transformers/pull/29038_load_best_model by @muellerzr in https://github.com/huggingface/transformers/pull/30553use_cache in kwargs for GPTNeoX by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30538use_square_size after loading by @ydshieh in https://github.com/huggingface/transformers/pull/30567output_router_logits in SwitchTransformers by @lausannel in https://github.com/huggingface/transformers/pull/30573contiguous() in clip checkpoint conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30613generate-related rendering issues by @gante in https://github.com/huggingface/transformers/pull/30600StoppingCriteria autodocs by @gante in https://github.com/huggingface/transformers/pull/30617SinkCache on Llama models by @gante in https://github.com/huggingface/transformers/pull/30581None as attention when layer is skipped by @jonghwanhyeon in https://github.com/huggingface/transformers/pull/30597TextGenerationPipeline._sanitize_parameters from overriding previously provided parameters by @yting27 in https://github.com/huggingface/transformers/pull/30362CI update] Try to use dockers and no cache by @ArthurZucker in https://github.com/huggingface/transformers/pull/29202resume_download deprecation by @Wauplin in https://github.com/huggingface/transformers/pull/30620cache_position initialisation for generation with use_cache=False by @nurlanov-zh in https://github.com/huggingface/transformers/pull/30485forward in Idefics2ForConditionalGeneration with correct ignore_index value by @zafstojano in https://github.com/huggingface/transformers/pull/30678workflow_id in utils/get_previous_daily_ci.py by @ydshieh in https://github.com/huggingface/transformers/pull/30695prev_ci_results to ci_results by @ydshieh in https://github.com/huggingface/transformers/pull/30697model.active_adapters() instead of deprecated model.active_adapter whenever possible by @younesbelkada in https://github.com/huggingface/transformers/pull/30738actions/post-slack with centrally defined workflow by @younesbelkada in https://github.com/huggingface/transformers/pull/30737model_parallel = False to T5ForTokenClassification and MT5ForTokenClassification by @retarfi in https://github.com/huggingface/transformers/pull/30763WhisperGenerationMixin by @cifkao in https://github.com/huggingface/transformers/pull/29688Optional in typing. by @xkszltl in https://github.com/huggingface/transformers/pull/30821torch 2.3 for CI by @ydshieh in https://github.com/huggingface/transformers/pull/30837Cache but not static cache by @gante in https://github.com/huggingface/transformers/pull/30800Full Changelog: https://github.com/huggingface/transformers/compare/v4.40.2...v4.41.0
The Phi-3 model was proposed in Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone by Microsoft.
TLDR; Phi-3 introduces new ROPE scaling methods, which seems to scale fairly well! A 3b and a Phi-3-mini is available in two context-length variants—4K and 128K tokens. It is the first model in its class to support a context window of up to 128K tokens, with little impact on quality.
JetMoe-8B is an 8B Mixture-of-Experts (MoE) language model developed by Yikang Shen and MyShell. JetMoe project aims to provide a LLaMA2-level performance and efficient language model with a limited budget. To achieve this goal, JetMoe uses a sparsely activated architecture inspired by the ModuleFormer. Each JetMoe block consists of two MoE layers: Mixture of Attention Heads and Mixture of MLP Experts. Given the input tokens, it activates a subset of its experts to process them. This sparse activation schema enables JetMoe to achieve much better training throughput than similar size dense models. The training throughput of JetMoe-8B is around 100B tokens per day on a cluster of 96 H100 GPUs with a straightforward 3-way pipeline parallelism strategy.
PaliGemma is a lightweight open vision-language model (VLM) inspired by PaLI-3, and based on open components like the SigLIP vision model and the Gemma language model. PaliGemma takes both images and text as inputs and can answer questions about images with detail and context, meaning that PaliGemma can perform deeper analysis of images and provide useful insights, such as captioning for images and short videos, object detection, and reading text embedded within images.
More than 120 checkpoints are released see the collection here !
Video-LLaVA exhibits remarkable interactive capabilities between images and videos, despite the absence of image-video pairs in the dataset.
💡 Simple baseline, learning united visual representation by alignment before projection With the binding of unified visual representations to the language feature space, we enable an LLM to perform visual reasoning capabilities on both images and videos simultaneously. 🔥 High performance, complementary learning with video and image Extensive experiments demonstrate the complementarity of modalities, showcasing significant superiority when compared to models specifically designed for either images or videos.
Two new models from TII-UAE! They published a blog-post with more details! Falcon2 introduces parallel mlp, and falcon VLM uses the Llava framework
from_pretrained supportYou can now load most of the GGUF quants directly with transformers' from_pretrained to convert it to a classic pytorch model. The API is simple:
from transformers import AutoTokenizer, AutoModelForCausalLM
model_id = "TheBloke/TinyLlama-1.1B-Chat-v1.0-GGUF"
filename = "tinyllama-1.1b-chat-v1.0.Q6_K.gguf"
tokenizer = AutoTokenizer.from_pretrained(model_id, gguf_file=filename)
model = AutoModelForCausalLM.from_pretrained(model_id, gguf_file=filename)
We plan more closer integrations with llama.cpp / GGML ecosystem in the future, see: https://github.com/huggingface/transformers/issues/27712 for more details
v4.41.0 introduces a significant refactor of the Agents framework.
With this release, we allow you to build state-of-the-art agent systems, including the React Code Agent that writes its actions as code in ReAct iterations, following the insights from Wang et al., 2024
Just install with pip install "transformers[agents]". Then you're good to go!
from transformers import ReactCodeAgent
agent = ReactCodeAgent(tools=[])
code = """
list=[0, 1, 2]
for i in range(4):
print(list(i))
"""
corrected_code = agent.run(
"I have some code that creates a bug: please debug it and return the final code",
code=code,
)
In this release we support new quantization methods: HQQ & EETQ contributed by the community. Read more about how to quantize any transformers model using HQQ & EETQ in the dedicated documentation section
dequantize API for bitsandbytes modelsIn case you want to dequantize models that have been loaded with bitsandbytes, this is now possible through the dequantize API (e.g. to merge adapter weights)
dequantize API for bitsandbytes quantized models by @younesbelkada in https://github.com/huggingface/transformers/pull/30806API-wise, you can achieve that with the following:
from transformers import AutoModelForCausalLM, BitsAndBytesConfig, AutoTokenizer
model_id = "facebook/opt-125m"
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=BitsAndBytesConfig(load_in_4bit=True))
tokenizer = AutoTokenizer.from_pretrained(model_id)
model.dequantize()
text = tokenizer("Hello my name is", return_tensors="pt").to(0)
out = model.generate(**text)
print(tokenizer.decode(out[0]))
min_p sampling by @gante in https://github.com/huggingface/transformers/pull/30639Gemma work with torch.compile by @ydshieh in https://github.com/huggingface/transformers/pull/30775BERT] Add support for sdpa by @hackyon in https://github.com/huggingface/transformers/pull/28802Addition of fine-tuning script for object detection models
Add interpolation of embeddings. This enables predictions from pretrained models on input images of sizes different than those the model was originally trained on. Simply pass interpolate_pos_embedding=True when calling the model.
Added for: BLIP, BLIP 2, InstructBLIP, SigLIP, ViViT
import requests
from PIL import Image
from transformers import Blip2Processor, Blip2ForConditionalGeneration
image = Image.open(requests.get("https://huggingface.co/hf-internal-testing/blip-test-image/resolve/main/demo.jpg", stream=True).raw)
processor = Blip2Processor.from_pretrained("Salesforce/blip2-opt-2.7b")
model = Blip2ForConditionalGeneration.from_pretrained(
"Salesforce/blip2-opt-2.7b",
torch_dtype=torch.float16
).to("cuda")
inputs = processor(images=image, size={"height": 500, "width": 500}, return_tensors="pt").to("cuda")
predictions = model(**inputs, interpolate_pos_encoding=True)
# Generated text: "a woman and dog on the beach"
generated_text = processor.batch_decode(predictions, skip_special_tokens=True)[0].strip()
evaluation_strategy to eval_strategy🚨🚨🚨 by @muellerzr in https://github.com/huggingface/transformers/pull/30190LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881prev_ci_results by @ydshieh in https://github.com/huggingface/transformers/pull/30313pad token id in pipeline forward arguments by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30285jnp import in utils/generic.py by @ydshieh in https://github.com/huggingface/transformers/pull/30322AssertionError in clip conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30321pad_token_id again by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30338Llama family, fix use_cache=False generation by @ArthurZucker in https://github.com/huggingface/transformers/pull/30380-rs to show skip reasons by @ArthurZucker in https://github.com/huggingface/transformers/pull/30318require_torch_sdpa for test that needs sdpa support by @faaany in https://github.com/huggingface/transformers/pull/30408LlamaTokenizerFast] Refactor default llama by @ArthurZucker in https://github.com/huggingface/transformers/pull/28881Llava] + CIs fix red cis and llava integration tests by @ArthurZucker in https://github.com/huggingface/transformers/pull/30440paths filter to avoid the chance of being triggered by @ydshieh in https://github.com/huggingface/transformers/pull/30453utils/check_if_new_model_added.py by @ydshieh in https://github.com/huggingface/transformers/pull/30456research_project] Most of the security issues come from this requirement.txt by @ArthurZucker in https://github.com/huggingface/transformers/pull/29977WandbCallback with third parties by @tomaarsen in https://github.com/huggingface/transformers/pull/30477SourceFileLoader.load_module() in dynamic module loading by @XuehaiPan in https://github.com/huggingface/transformers/pull/30370HfQuantizer quant method update by @younesbelkada in https://github.com/huggingface/transformers/pull/30484bitsandbytes error formatting ("Some modules are dispatched on ...") by @kyo-takano in https://github.com/huggingface/transformers/pull/30494dtype_byte_size to handle torch.float8_e4m3fn/float8_e5m2 types by @mgoin in https://github.com/huggingface/transformers/pull/30488DETR] Remove timm hardcoded logic in modeling files by @amyeroberts in https://github.com/huggingface/transformers/pull/29038_load_best_model by @muellerzr in https://github.com/huggingface/transformers/pull/30553use_cache in kwargs for GPTNeoX by @zucchini-nlp in https://github.com/huggingface/transformers/pull/30538use_square_size after loading by @ydshieh in https://github.com/huggingface/transformers/pull/30567output_router_logits in SwitchTransformers by @lausannel in https://github.com/huggingface/transformers/pull/30573contiguous() in clip checkpoint conversion script by @ydshieh in https://github.com/huggingface/transformers/pull/30613generate-related rendering issues by @gante in https://github.com/huggingface/transformers/pull/30600StoppingCriteria autodocs by @gante in https://github.com/huggingface/transformers/pull/30617SinkCache on Llama models by @gante in https://github.com/huggingface/transformers/pull/30581None as attention when layer is skipped by @jonghwanhyeon in https://github.com/huggingface/transformers/pull/30597TextGenerationPipeline._sanitize_parameters from overriding previously provided parameters by @yting27 in https://github.com/huggingface/transformers/pull/30362CI update] Try to use dockers and no cache by @ArthurZucker in https://github.com/huggingface/transformers/pull/29202resume_download deprecation by @Wauplin in https://github.com/huggingface/transformers/pull/30620cache_position initialisation for generation with use_cache=False by @nurlanov-zh in https://github.com/huggingface/transformers/pull/30485forward in Idefics2ForConditionalGeneration with correct ignore_index value by @zafstojano in https://github.com/huggingface/transformers/pull/30678workflow_id in utils/get_previous_daily_ci.py by @ydshieh in https://github.com/huggingface/transformers/pull/30695prev_ci_results to ci_results by @ydshieh in https://github.com/huggingface/transformers/pull/30697model.active_adapters() instead of deprecated model.active_adapter whenever possible by @younesbelkada in https://github.com/huggingface/transformers/pull/30738actions/post-slack with centrally defined workflow by @younesbelkada in https://github.com/huggingface/transformers/pull/30737model_parallel = False to T5ForTokenClassification and MT5ForTokenClassification by @retarfi in https://github.com/huggingface/transformers/pull/30763WhisperGenerationMixin by @cifkao in https://github.com/huggingface/transformers/pull/29688Optional in typing. by @xkszltl in https://github.com/huggingface/transformers/pull/30821torch 2.3 for CI by @ydshieh in https://github.com/huggingface/transformers/pull/30837Cache but not static cache by @gante in https://github.com/huggingface/transformers/pull/30800Full Changelog: https://github.com/huggingface/transformers/compare/v4.40.2...v4.41.0