huggingface/transformers
huggingface/transformers
Activity
Last release
Open issues
Open PRs
License
release notes
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.
release notes
Published 4/18/2024
MinorContains breaking changesrelease notes
Published 4/18/2024
MinorContains breaking changesLlama 3 is supported in this release through the Llama 2 architecture and some fixes in the tokenizers library.

The Idefics2 model was created by the Hugging Face M4 team and authored by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found here.
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs. It improves upon IDEFICS-1, notably on document understanding, OCR, or visual reasoning. Idefics2 is lightweight (8 billion parameters) and treats images in their native aspect ratio and resolution, which allows for varying inference efficiency.
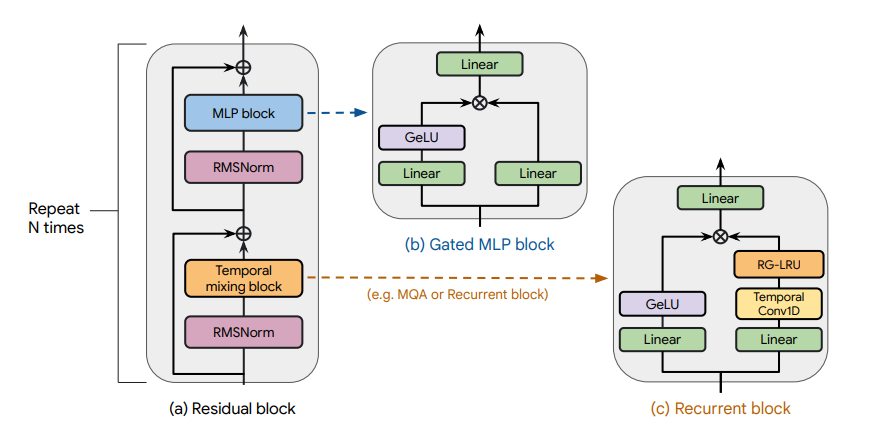
Recurrent Gemma architecture. Taken from the original paper.
The Recurrent Gemma model was proposed in RecurrentGemma: Moving Past Transformers for Efficient Open Language Models by the Griffin, RLHF and Gemma Teams of Google.
The abstract from the paper is the following:
We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
As depicted in the diagram below, Jamba’s architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
Jamba introduces the first HybridCache object that allows it to natively support assisted generation, contrastive search, speculative decoding, beam search and all of the awesome features from the generate API!
DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
This provides 65x more possible combinations of experts and the authors found that this improves model quality. DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
The OLMo model was proposed in OLMo: Accelerating the Science of Language Models by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of Open Language Models designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Model Details Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, Qwen1.5-MoE-A2.7B is upcycled from Qwen-1.8B. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with Qwen1.5-7B, with only 25% of the training resources.
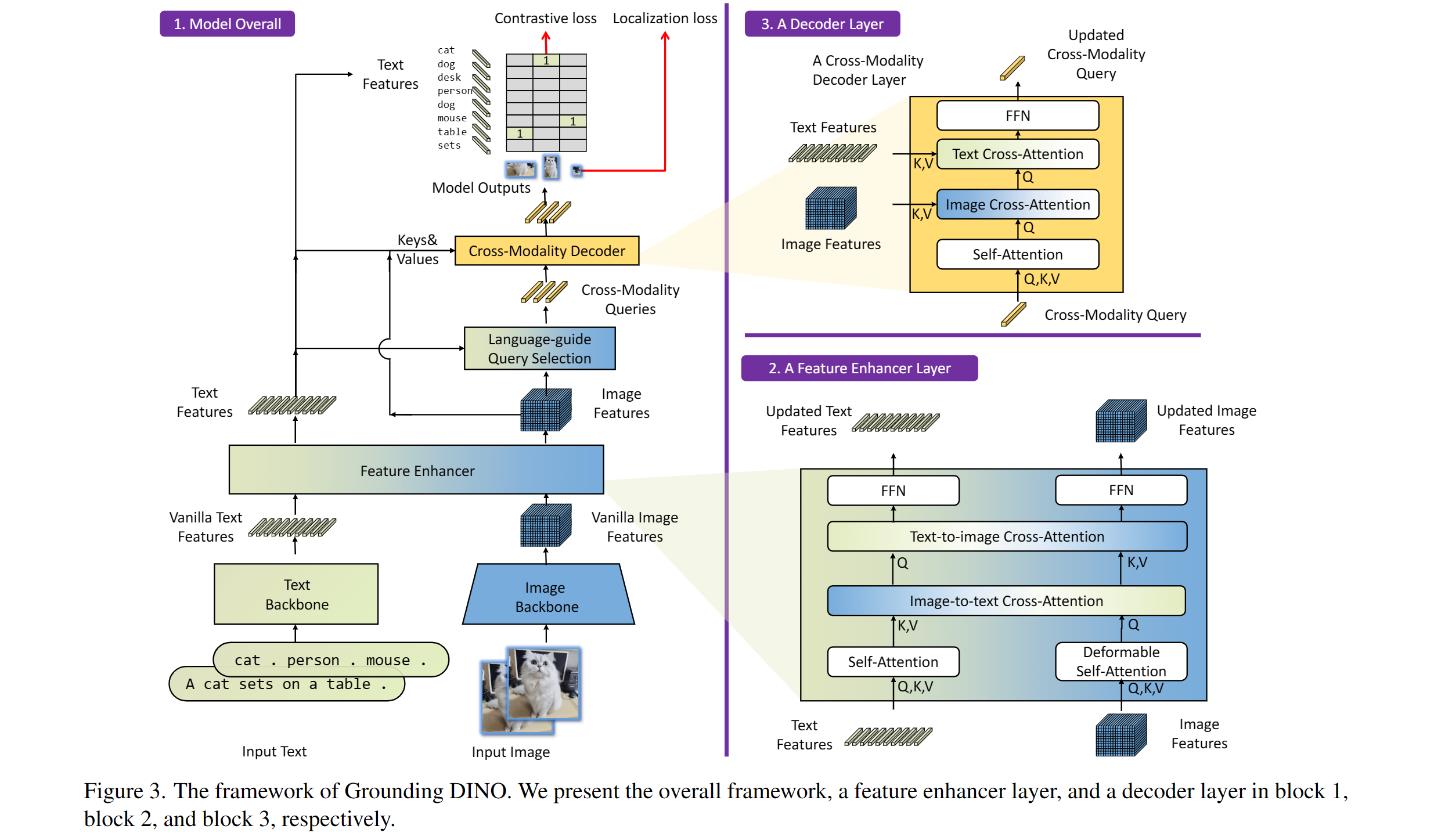
Taken from the original paper.
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
Static pretrained maps have been removed from the library's internals and are currently deprecated. These used to reflect all the available checkpoints for a given architecture on the Hugging Face Hub, but their presence does not make sense in light of the huge growth of checkpoint shared by the community.
With the objective of lowering the bar of model contributions and reviewing, we first start by removing legacy objects such as this one which do not serve a purpose.
Processors are ungoing changes in order to uniformize them and make them clearer to use.
Pipelines can now be pushed to Hub using a convenient push_to_hub method.
Thanks to the community contribution, Flash Attention 2 has been integrated for more architectures
- and the from custom_tools.md by @windsonsea in #29767-OO mode for docstring_decorator by @matthid in #29689Latest PyTorch + TensorFlow [dev] by @ydshieh in #29764LlavaNext] Fix llava next unsafe imports by @ArthurZucker in #29773set_seed by @muellerzr in #29778torch_dtype in the run_mlm example by @jla524 in #29776bos token to Blip generations by @zucchini-nlp in #29642quality] update quality check to make sure we check imports 😈 by @ArthurZucker in #29771vocab_size by @fxmarty in #29389AssistedCandidateGenerator by @gante in #29787cleanup] vestiges of causal mask by @ArthurZucker in #29806SuperPoint] Fix doc example by @amyeroberts in #29816bos_token_id is None during the generation with inputs_embeds by @LZHgrla in #29772cosine_with_min_lr scheduler in Trainer by @liuyanyi in #29341num_attention_heads != num_key_value_heads in Flax Llama Implementation by @bminixhofer in #29557slow_forward gradient fix by @vasqu in #29563eos_token_id to stopping criteria by @zucchini-nlp in #29459make fix-copies] update and help by @ArthurZucker in #29924GptNeox] don't gather on pkv when using the trainer by @ArthurZucker in #29892pipeline]. Zero shot add doc warning by @ArthurZucker in #29845xpu to the testing documentation by @faaany in #29894torch.testing.assert_allclose by torch.testing.assert_close by @gante in #29915Mamba] from pretrained issue with self.embeddings by @ArthurZucker in #29851TokenizationLlama] fix the way we convert tokens to strings to keep leading spaces 🚨 breaking fix by @ArthurZucker in #29453BC] Fix BC for other libraries by @ArthurZucker in #29934LlamaSlowConverter] Slow to Fast better support by @ArthurZucker in #29797StableLm] Add QK normalization and Parallel Residual Support by @jon-tow in #29745test_eager_matches_sdpa_generate flaky for some models by @ydshieh in #29479run_qa.py by @jla524 in #29867BC] Fix BC for AWQ quant by @TechxGenus in #29965ImageToTextPipelineTests.test_conditional_generation_llava by @faaany in #29975generate] fix breaking change for patch by @ArthurZucker in #29976_replace_with_bnb_linear by @SunMarc in #29958skip_special_tokens for Wav2Vec2CTCTokenizer._decode by @msublee in #29311remove_columns in text-classification example by @mariosasko in #29351tests/utils/tiny_model_summary.json by @ydshieh in #29941kwargs handling in generate_with_fallback by @cifkao in #29225WhisperNoSpeechDetection when recomputing scores by @cifkao in #29248Main CIs] Fix the red cis by @ArthurZucker in #30022ProcessingIdefics] Attention mask bug with padding by @byi8220 in #29449whisper to IMPORTANT_MODELS by @ydshieh in #30046test_encode_decode_fast_slow_all_tokens for now by @ydshieh in #30044llm_int8_enable_fp32_cpu_offload=True...." instead of "load_in_8bit_fp32_cpu_offload=True". by @miRx923 in #30013torch.fx symbolic tracing for LLama by @michaelbenayoun in #30047require_bitsandbytes marker by @faaany in #30116mps as device for Pipeline class by @fnhirwa in #30080itemize by @younesbelkada in #30162ruff configuration to avoid deprecated configuration warning by @Sai-Suraj-27 in #30179CI] Add new workflow to run slow tests of important models on push main if they are modified by @younesbelkada in #29235logger.warn with logger.warning by @Sai-Suraj-27 in #30197RecurrentGemmaIntegrationTest.test_2b_sample by @ydshieh in #30222assertEquals with assertEqual by @Sai-Suraj-27 in #30241typing.Text with str by @Sai-Suraj-27 in #30230type annotation for compatability with python 3.8 by @Sai-Suraj-27 in #30243docs/source/en) by @ydshieh in #30247require_torch_multi_gpu flag by @faaany in #30250ko/_toctree.yml by @jungnerd in #30062raise statement by @Sai-Suraj-27 in #30275Idefics2's doc example by @ydshieh in #30274ExamplesTests::test_run_translation by @ydshieh in #30281Fatal Python error: Bus error in ZeroShotAudioClassificationPipelineTests by @ydshieh in #30283The following contributors have made significant changes to the library over the last release:
Llama 3 is supported in this release through the Llama 2 architecture and some fixes in the tokenizers library.
The Idefics2 model was created by the Hugging Face M4 team and authored by Léo Tronchon, Hugo Laurencon, Victor Sanh. The accompanying blog post can be found here.
Idefics2 is an open multimodal model that accepts arbitrary sequences of image and text inputs and produces text outputs. The model can answer questions about images, describe visual content, create stories grounded on multiple images, or simply behave as a pure language model without visual inputs. It improves upon IDEFICS-1, notably on document understanding, OCR, or visual reasoning. Idefics2 is lightweight (8 billion parameters) and treats images in their native aspect ratio and resolution, which allows for varying inference efficiency.
Recurrent Gemma architecture. Taken from the original paper.
The Recurrent Gemma model was proposed in RecurrentGemma: Moving Past Transformers for Efficient Open Language Models by the Griffin, RLHF and Gemma Teams of Google.
The abstract from the paper is the following:
We introduce RecurrentGemma, an open language model which uses Google’s novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Jamba is a pretrained, mixture-of-experts (MoE) generative text model, with 12B active parameters and an overall of 52B parameters across all experts. It supports a 256K context length, and can fit up to 140K tokens on a single 80GB GPU.
As depicted in the diagram below, Jamba’s architecture features a blocks-and-layers approach that allows Jamba to successfully integrate Transformer and Mamba architectures altogether. Each Jamba block contains either an attention or a Mamba layer, followed by a multi-layer perceptron (MLP), producing an overall ratio of one Transformer layer out of every eight total layers.
Jamba introduces the first HybridCache object that allows it to natively support assisted generation, contrastive search, speculative decoding, beam search and all of the awesome features from the generate API!
DBRX is a transformer-based decoder-only large language model (LLM) that was trained using next-token prediction. It uses a fine-grained mixture-of-experts (MoE) architecture with 132B total parameters of which 36B parameters are active on any input.
It was pre-trained on 12T tokens of text and code data. Compared to other open MoE models like Mixtral-8x7B and Grok-1, DBRX is fine-grained, meaning it uses a larger number of smaller experts. DBRX has 16 experts and chooses 4, while Mixtral-8x7B and Grok-1 have 8 experts and choose 2.
This provides 65x more possible combinations of experts and the authors found that this improves model quality. DBRX uses rotary position encodings (RoPE), gated linear units (GLU), and grouped query attention (GQA).
The OLMo model was proposed in OLMo: Accelerating the Science of Language Models by Dirk Groeneveld, Iz Beltagy, Pete Walsh, Akshita Bhagia, Rodney Kinney, Oyvind Tafjord, Ananya Harsh Jha, Hamish Ivison, Ian Magnusson, Yizhong Wang, Shane Arora, David Atkinson, Russell Authur, Khyathi Raghavi Chandu, Arman Cohan, Jennifer Dumas, Yanai Elazar, Yuling Gu, Jack Hessel, Tushar Khot, William Merrill, Jacob Morrison, Niklas Muennighoff, Aakanksha Naik, Crystal Nam, Matthew E. Peters, Valentina Pyatkin, Abhilasha Ravichander, Dustin Schwenk, Saurabh Shah, Will Smith, Emma Strubell, Nishant Subramani, Mitchell Wortsman, Pradeep Dasigi, Nathan Lambert, Kyle Richardson, Luke Zettlemoyer, Jesse Dodge, Kyle Lo, Luca Soldaini, Noah A. Smith, Hannaneh Hajishirzi.
OLMo is a series of Open Language Models designed to enable the science of language models. The OLMo models are trained on the Dolma dataset. We release all code, checkpoints, logs (coming soon), and details involved in training these models.
Qwen2MoE is the new model series of large language models from the Qwen team. Previously, we released the Qwen series, including Qwen-72B, Qwen-1.8B, Qwen-VL, Qwen-Audio, etc.
Model Details Qwen2MoE is a language model series including decoder language models of different model sizes. For each size, we release the base language model and the aligned chat model. Qwen2MoE has the following architectural choices:
Qwen2MoE is based on the Transformer architecture with SwiGLU activation, attention QKV bias, group query attention, mixture of sliding window attention and full attention, etc. Additionally, we have an improved tokenizer adaptive to multiple natural languages and codes. Qwen2MoE employs Mixture of Experts (MoE) architecture, where the models are upcycled from dense language models. For instance, Qwen1.5-MoE-A2.7B is upcycled from Qwen-1.8B. It has 14.3B parameters in total and 2.7B activated parameters during runtime, while it achieves comparable performance with Qwen1.5-7B, with only 25% of the training resources.
Taken from the original paper.
The Grounding DINO model was proposed in Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection by Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, Lei Zhang. Grounding DINO extends a closed-set object detection model with a text encoder, enabling open-set object detection. The model achieves remarkable results, such as 52.5 AP on COCO zero-shot.
Static pretrained maps have been removed from the library's internals and are currently deprecated. These used to reflect all the available checkpoints for a given architecture on the Hugging Face Hub, but their presence does not make sense in light of the huge growth of checkpoint shared by the community.
With the objective of lowering the bar of model contributions and reviewing, we first start by removing legacy objects such as this one which do not serve a purpose.
Processors are ungoing changes in order to uniformize them and make them clearer to use.
Pipelines can now be pushed to Hub using a convenient push_to_hub method.
Thanks to the community contribution, Flash Attention 2 has been integrated for more architectures
- and the from custom_tools.md by @windsonsea in #29767-OO mode for docstring_decorator by @matthid in #29689Latest PyTorch + TensorFlow [dev] by @ydshieh in #29764LlavaNext] Fix llava next unsafe imports by @ArthurZucker in #29773set_seed by @muellerzr in #29778torch_dtype in the run_mlm example by @jla524 in #29776bos token to Blip generations by @zucchini-nlp in #29642quality] update quality check to make sure we check imports 😈 by @ArthurZucker in #29771vocab_size by @fxmarty in #29389AssistedCandidateGenerator by @gante in #29787cleanup] vestiges of causal mask by @ArthurZucker in #29806SuperPoint] Fix doc example by @amyeroberts in #29816bos_token_id is None during the generation with inputs_embeds by @LZHgrla in #29772cosine_with_min_lr scheduler in Trainer by @liuyanyi in #29341num_attention_heads != num_key_value_heads in Flax Llama Implementation by @bminixhofer in #29557slow_forward gradient fix by @vasqu in #29563eos_token_id to stopping criteria by @zucchini-nlp in #29459make fix-copies] update and help by @ArthurZucker in #29924GptNeox] don't gather on pkv when using the trainer by @ArthurZucker in #29892pipeline]. Zero shot add doc warning by @ArthurZucker in #29845xpu to the testing documentation by @faaany in #29894torch.testing.assert_allclose by torch.testing.assert_close by @gante in #29915Mamba] from pretrained issue with self.embeddings by @ArthurZucker in #29851TokenizationLlama] fix the way we convert tokens to strings to keep leading spaces 🚨 breaking fix by @ArthurZucker in #29453BC] Fix BC for other libraries by @ArthurZucker in #29934LlamaSlowConverter] Slow to Fast better support by @ArthurZucker in #29797StableLm] Add QK normalization and Parallel Residual Support by @jon-tow in #29745test_eager_matches_sdpa_generate flaky for some models by @ydshieh in #29479run_qa.py by @jla524 in #29867BC] Fix BC for AWQ quant by @TechxGenus in #29965ImageToTextPipelineTests.test_conditional_generation_llava by @faaany in #29975generate] fix breaking change for patch by @ArthurZucker in #29976_replace_with_bnb_linear by @SunMarc in #29958skip_special_tokens for Wav2Vec2CTCTokenizer._decode by @msublee in #29311remove_columns in text-classification example by @mariosasko in #29351tests/utils/tiny_model_summary.json by @ydshieh in #29941kwargs handling in generate_with_fallback by @cifkao in #29225WhisperNoSpeechDetection when recomputing scores by @cifkao in #29248Main CIs] Fix the red cis by @ArthurZucker in #30022ProcessingIdefics] Attention mask bug with padding by @byi8220 in #29449whisper to IMPORTANT_MODELS by @ydshieh in #30046test_encode_decode_fast_slow_all_tokens for now by @ydshieh in #30044llm_int8_enable_fp32_cpu_offload=True...." instead of "load_in_8bit_fp32_cpu_offload=True". by @miRx923 in #30013torch.fx symbolic tracing for LLama by @michaelbenayoun in #30047require_bitsandbytes marker by @faaany in #30116mps as device for Pipeline class by @fnhirwa in #30080itemize by @younesbelkada in #30162ruff configuration to avoid deprecated configuration warning by @Sai-Suraj-27 in #30179CI] Add new workflow to run slow tests of important models on push main if they are modified by @younesbelkada in #29235logger.warn with logger.warning by @Sai-Suraj-27 in #30197RecurrentGemmaIntegrationTest.test_2b_sample by @ydshieh in #30222assertEquals with assertEqual by @Sai-Suraj-27 in #30241typing.Text with str by @Sai-Suraj-27 in #30230type annotation for compatability with python 3.8 by @Sai-Suraj-27 in #30243docs/source/en) by @ydshieh in #30247require_torch_multi_gpu flag by @faaany in #30250ko/_toctree.yml by @jungnerd in #30062raise statement by @Sai-Suraj-27 in #30275Idefics2's doc example by @ydshieh in #30274ExamplesTests::test_run_translation by @ydshieh in #30281Fatal Python error: Bus error in ZeroShotAudioClassificationPipelineTests by @ydshieh in #30283The following contributors have made significant changes to the library over the last release: