huggingface/transformers
huggingface/transformers
Activity
Last release
Open issues
Open PRs
License
release notes
release notes
Published 3/21/2024
MinorContains breaking changesThe Llama, Cohere and the Gemma model both no longer cache the triangular causal mask unless static cache is used. This was reverted by #29753, which fixes the BC issues w.r.t speed , and memory consumption, while still supporting compile and static cache. Small note, fx is not supported for both models, a patch will be brought very soon!
Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with Cohere's industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
Llava next is the next version of Llava, which includes better support for non padded images, improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
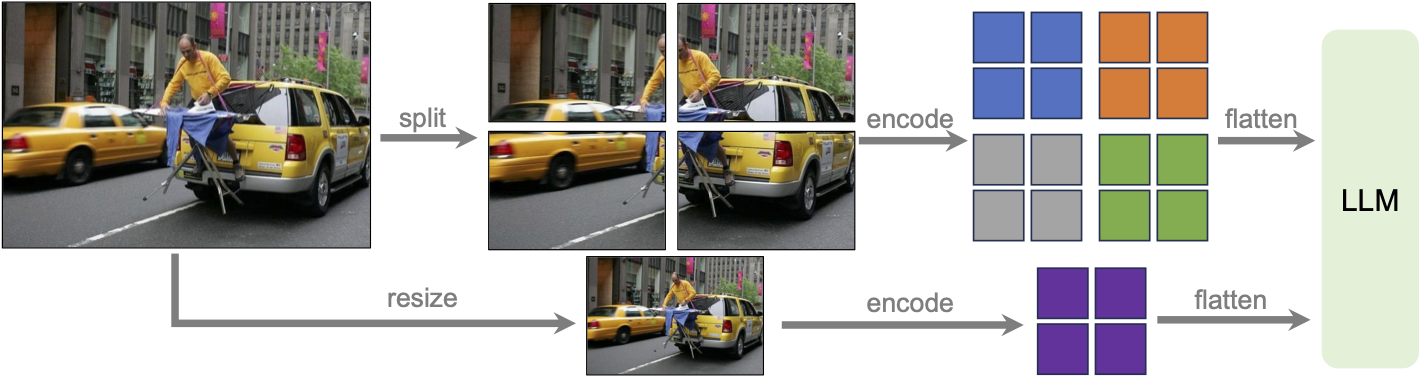
LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
The MusicGen Melody model was proposed in Simple and Controllable Music Generation by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or audio codes, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
The PVTv2 model was proposed in PVT v2: Improved Baselines with Pyramid Vision Transformer by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
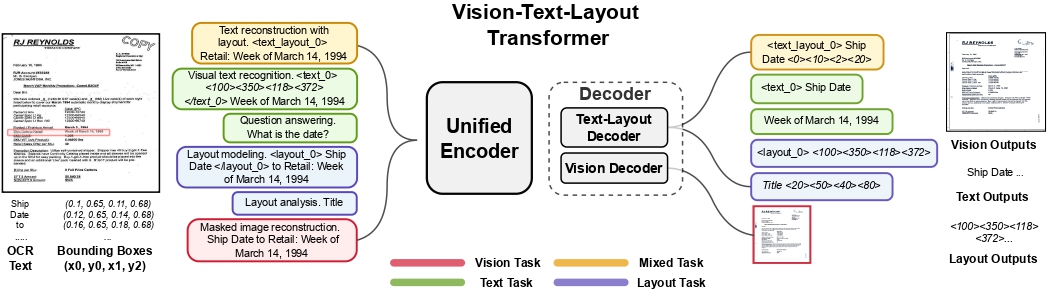
UDOP architecture. Taken from the original paper.
This model is a new paradigm architecture based on state-space-models, rather than attention like transformer models. The checkpoints are compatible with the original ones
Add Mamba] Adds support for the Mamba models by @ArthurZucker in #28094StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
The SegGPT model was proposed in SegGPT: Segmenting Everything In Context by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.

With Galore, you can pre-train large models on consumer-type hardwares, making LLM pre-training much more accessible to anyone from the community.
Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Galore is based on low rank approximation of the gradients and can be used out of the box for any model.
Below is a simple snippet that demonstrates how to pre-train mistralai/Mistral-7B-v0.1 on imdb:
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
Quanto has been integrated with transformers ! You can apply simple quantization algorithms with few lines of code with tiny changes. Quanto is also compatible with torch.compile
Check out the announcement blogpost for more details
Exllama and AWQ combined together for faster AWQ inference - check out the relevant documentation section for more details on how to use Exllama + AWQ.
Allow models saved or fine-tuned with Apple’s MLX framework to be loaded in transformers (as long as the model parameters use the same names), and improve tensor interoperability. This leverages MLX's adoption of safetensors as their checkpoint format.
Notable memory reduction in Gemma/LLaMa by changing the causal mask buffer type from int64 to boolean.
The PRs below introduced slightly breaking changes that we believed was necessary for the repository; if these seem to impact your usage of transformers, we recommend checking out the PR description to get more insights in how to leverage the new behavior.
Gemma] Fix bad rebase with transformers main by @younesbelkada in #29170torch.compile with fullgraph=True when attention_mask input is used by @fxmarty in #29211Doc] update model doc qwen2 by @ArthurZucker in #29238is_vision_available result by @bmuskalla in #29280DS_DISABLE_NINJA=1 by @ydshieh in #29290non_device_test pytest mark to filter out non-device tests by @fxmarty in #29213dtype and device extraction for CUDA graph generation for quantizers compatibility by @BlackSamorez in #29079attn_implementation documentation by @fxmarty in #29295GenerationMixin's docstring by @sadra-barikbin in #29277Gemma / CI] Make sure our runners have access to the model by @younesbelkada in #29242require_read_token] fix typo by @ArthurZucker in #29345T5 and Llama Tokenizer] remove warning by @ArthurZucker in #29346Llama ROPE] Fix torch export but also slow downs in forward by @ArthurZucker in #29198output_router_logits during inference by @LeonardoEmili in #29249CI / starcoder2] Change starcoder2 path to correct one for slow tests by @younesbelkada in #29359CI]: Fix failing tests for peft integration by @younesbelkada in #29330CI] require_read_token in the llama FA2 test by @younesbelkada in #29361get_values(MODEL_MAPPING) by @ydshieh in #29362offload_buffers parameter of accelerate to PreTrainedModel.from_pretrained method by @notsyncing in #28755quantization / ESM] Fix ESM 8bit / 4bit with bitsandbytes by @younesbelkada in #29329Llama + AWQ] fix prepare_inputs_for_generation 🫠 by @ArthurZucker in #29381YOLOS] Fix - return padded annotations by @amyeroberts in #29300AutoProcessor by @JingyaHuang in #29169post_process_instance_segmentation for panoptic tasks by @nickthegroot in #29304Generation] Fix some issues when running the MaxLength criteria on CPU by @younesbelkada in #29317UdopTokenizer] Fix post merge imports by @ArthurZucker in #29451Udop imports] Processor tests were not run. by @ArthurZucker in #29456import_path location by @loadams in #29154offload_weight() takes from 3 to 4 positional arguments but 5 were given by @faaany in #29457Docs / Awq] Add docs on exllamav2 + AWQ by @younesbelkada in #29474docs] Add starcoder2 docs by @younesbelkada in #29454pad_to_multiple_of by @gante in #29462TextGenerationPipeline.__call__ docstring by @alvarobartt in #29491inputs as kwarg in TextClassificationPipeline by @alvarobartt in #29495VisionEncoderDecoder Positional Arg by @nickthegroot in #29497require_sacremoses decorator by @faaany in #29504torch_device instead of auto for model testing by @faaany in #29531TrainingArguments by @yundai424 in #29189n_gpu in TrainerIntegrationTest::test_train_and_eval_dataloaders for XPU by @faaany in #29307warning_advice for tensorflow warning by @winstxnhdw in #29540Mamba doc] Post merge updates by @ArthurZucker in #29472Docs] fixed minor typo by @j-gc in #29555main branch by @ydshieh in #28816max_position_embeddings in the translation example by @gante in #29600Gemma] Supports converting directly in half-precision by @younesbelkada in #29529MaskFormer, Mask2Former] Use einsum where possible by @amyeroberts in #29544Mask2Former] Move normalization for numerical stability by @amyeroberts in #29542test_trainer_log_level_replica to run on accelerators with more than 2 devices by @faaany in #29609multi_gpu_data_parallel_forward for MusicgenTest by @ydshieh in #29632PEFT] Fix save_pretrained to make sure adapters weights are also saved on TPU by @shub-kris in #29388dataset_revision argument to RagConfig by @ydshieh in #29610cache_position update in generate by @gante in #29467generation_config by @gante in #29675filter_models by @ydshieh in #29673glue to nyu-mll/glue by @lhoestq in #29679filter_models" by @ydshieh in #29682filter_models by @ydshieh in #29710bnb] Make unexpected_keys optional by @younesbelkada in #29420gradio.Interface.from_pipeline by @abidlabs in #29684The following contributors have made significant changes to the library over the last release:
release notes
Published 3/21/2024
MinorContains breaking changesThe Llama, Cohere and the Gemma model both no longer cache the triangular causal mask unless static cache is used. This was reverted by #29753, which fixes the BC issues w.r.t speed , and memory consumption, while still supporting compile and static cache. Small note, fx is not supported for both models, a patch will be brought very soon!
Command-R is a generative model optimized for long context tasks such as retrieval augmented generation (RAG) and using external APIs and tools. It is designed to work in concert with Cohere's industry-leading Embed and Rerank models to provide best-in-class integration for RAG applications and excel at enterprise use cases. As a model built for companies to implement at scale, Command-R boasts:
Llava next is the next version of Llava, which includes better support for non padded images, improved reasoning, OCR, and world knowledge. LLaVA-NeXT even exceeds Gemini Pro on several benchmarks.
Compared with LLaVA-1.5, LLaVA-NeXT has several improvements:
LLaVa-NeXT incorporates a higher input resolution by encoding various patches of the input image. Taken from the original paper.
The MusicGen Melody model was proposed in Simple and Controllable Music Generation by Jade Copet, Felix Kreuk, Itai Gat, Tal Remez, David Kant, Gabriel Synnaeve, Yossi Adi and Alexandre Défossez.
MusicGen Melody is a single stage auto-regressive Transformer model capable of generating high-quality music samples conditioned on text descriptions or audio prompts. The text descriptions are passed through a frozen text encoder model to obtain a sequence of hidden-state representations. MusicGen is then trained to predict discrete audio tokens, or audio codes, conditioned on these hidden-states. These audio tokens are then decoded using an audio compression model, such as EnCodec, to recover the audio waveform.
Through an efficient token interleaving pattern, MusicGen does not require a self-supervised semantic representation of the text/audio prompts, thus eliminating the need to cascade multiple models to predict a set of codebooks (e.g. hierarchically or upsampling). Instead, it is able to generate all the codebooks in a single forward pass.
The PVTv2 model was proposed in PVT v2: Improved Baselines with Pyramid Vision Transformer by Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, and Ling Shao. As an improved variant of PVT, it eschews position embeddings, relying instead on positional information encoded through zero-padding and overlapping patch embeddings. This lack of reliance on position embeddings simplifies the architecture, and enables running inference at any resolution without needing to interpolate them.
The UDOP model was proposed in Unifying Vision, Text, and Layout for Universal Document Processing by Zineng Tang, Ziyi Yang, Guoxin Wang, Yuwei Fang, Yang Liu, Chenguang Zhu, Michael Zeng, Cha Zhang, Mohit Bansal. UDOP adopts an encoder-decoder Transformer architecture based on T5 for document AI tasks like document image classification, document parsing and document visual question answering.
UDOP architecture. Taken from the original paper.
This model is a new paradigm architecture based on state-space-models, rather than attention like transformer models. The checkpoints are compatible with the original ones
Add Mamba] Adds support for the Mamba models by @ArthurZucker in #28094StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
The SegGPT model was proposed in SegGPT: Segmenting Everything In Context by Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang. SegGPT employs a decoder-only Transformer that can generate a segmentation mask given an input image, a prompt image and its corresponding prompt mask. The model achieves remarkable one-shot results with 56.1 mIoU on COCO-20 and 85.6 mIoU on FSS-1000.
With Galore, you can pre-train large models on consumer-type hardwares, making LLM pre-training much more accessible to anyone from the community.
Our approach reduces memory usage by up to 65.5% in optimizer states while maintaining both efficiency and performance for pre-training on LLaMA 1B and 7B architectures with C4 dataset with up to 19.7B tokens, and on fine-tuning RoBERTa on GLUE tasks. Our 8-bit GaLore further reduces optimizer memory by up to 82.5% and total training memory by 63.3%, compared to a BF16 baseline. Notably, we demonstrate, for the first time, the feasibility of pre-training a 7B model on consumer GPUs with 24GB memory (e.g., NVIDIA RTX 4090) without model parallel, checkpointing, or offloading strategies.
Galore is based on low rank approximation of the gradients and can be used out of the box for any model.
Below is a simple snippet that demonstrates how to pre-train mistralai/Mistral-7B-v0.1 on imdb:
import torch
import datasets
from transformers import TrainingArguments, AutoConfig, AutoTokenizer, AutoModelForCausalLM
import trl
train_dataset = datasets.load_dataset('imdb', split='train')
args = TrainingArguments(
output_dir="./test-galore",
max_steps=100,
per_device_train_batch_size=2,
optim="galore_adamw",
optim_target_modules=["attn", "mlp"]
)
model_id = "mistralai/Mistral-7B-v0.1"
config = AutoConfig.from_pretrained(model_id)
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_config(config).to(0)
trainer = trl.SFTTrainer(
model=model,
args=args,
train_dataset=train_dataset,
dataset_text_field='text',
max_seq_length=512,
)
trainer.train()
Quanto has been integrated with transformers ! You can apply simple quantization algorithms with few lines of code with tiny changes. Quanto is also compatible with torch.compile
Check out the announcement blogpost for more details
Exllama and AWQ combined together for faster AWQ inference - check out the relevant documentation section for more details on how to use Exllama + AWQ.
Allow models saved or fine-tuned with Apple’s MLX framework to be loaded in transformers (as long as the model parameters use the same names), and improve tensor interoperability. This leverages MLX's adoption of safetensors as their checkpoint format.
Notable memory reduction in Gemma/LLaMa by changing the causal mask buffer type from int64 to boolean.
The PRs below introduced slightly breaking changes that we believed was necessary for the repository; if these seem to impact your usage of transformers, we recommend checking out the PR description to get more insights in how to leverage the new behavior.
Gemma] Fix bad rebase with transformers main by @younesbelkada in #29170torch.compile with fullgraph=True when attention_mask input is used by @fxmarty in #29211Doc] update model doc qwen2 by @ArthurZucker in #29238is_vision_available result by @bmuskalla in #29280DS_DISABLE_NINJA=1 by @ydshieh in #29290non_device_test pytest mark to filter out non-device tests by @fxmarty in #29213dtype and device extraction for CUDA graph generation for quantizers compatibility by @BlackSamorez in #29079attn_implementation documentation by @fxmarty in #29295GenerationMixin's docstring by @sadra-barikbin in #29277Gemma / CI] Make sure our runners have access to the model by @younesbelkada in #29242require_read_token] fix typo by @ArthurZucker in #29345T5 and Llama Tokenizer] remove warning by @ArthurZucker in #29346Llama ROPE] Fix torch export but also slow downs in forward by @ArthurZucker in #29198output_router_logits during inference by @LeonardoEmili in #29249CI / starcoder2] Change starcoder2 path to correct one for slow tests by @younesbelkada in #29359CI]: Fix failing tests for peft integration by @younesbelkada in #29330CI] require_read_token in the llama FA2 test by @younesbelkada in #29361get_values(MODEL_MAPPING) by @ydshieh in #29362offload_buffers parameter of accelerate to PreTrainedModel.from_pretrained method by @notsyncing in #28755quantization / ESM] Fix ESM 8bit / 4bit with bitsandbytes by @younesbelkada in #29329Llama + AWQ] fix prepare_inputs_for_generation 🫠 by @ArthurZucker in #29381YOLOS] Fix - return padded annotations by @amyeroberts in #29300AutoProcessor by @JingyaHuang in #29169post_process_instance_segmentation for panoptic tasks by @nickthegroot in #29304Generation] Fix some issues when running the MaxLength criteria on CPU by @younesbelkada in #29317UdopTokenizer] Fix post merge imports by @ArthurZucker in #29451Udop imports] Processor tests were not run. by @ArthurZucker in #29456import_path location by @loadams in #29154offload_weight() takes from 3 to 4 positional arguments but 5 were given by @faaany in #29457Docs / Awq] Add docs on exllamav2 + AWQ by @younesbelkada in #29474docs] Add starcoder2 docs by @younesbelkada in #29454pad_to_multiple_of by @gante in #29462TextGenerationPipeline.__call__ docstring by @alvarobartt in #29491inputs as kwarg in TextClassificationPipeline by @alvarobartt in #29495VisionEncoderDecoder Positional Arg by @nickthegroot in #29497require_sacremoses decorator by @faaany in #29504torch_device instead of auto for model testing by @faaany in #29531TrainingArguments by @yundai424 in #29189n_gpu in TrainerIntegrationTest::test_train_and_eval_dataloaders for XPU by @faaany in #29307warning_advice for tensorflow warning by @winstxnhdw in #29540Mamba doc] Post merge updates by @ArthurZucker in #29472Docs] fixed minor typo by @j-gc in #29555main branch by @ydshieh in #28816max_position_embeddings in the translation example by @gante in #29600Gemma] Supports converting directly in half-precision by @younesbelkada in #29529MaskFormer, Mask2Former] Use einsum where possible by @amyeroberts in #29544Mask2Former] Move normalization for numerical stability by @amyeroberts in #29542test_trainer_log_level_replica to run on accelerators with more than 2 devices by @faaany in #29609multi_gpu_data_parallel_forward for MusicgenTest by @ydshieh in #29632PEFT] Fix save_pretrained to make sure adapters weights are also saved on TPU by @shub-kris in #29388dataset_revision argument to RagConfig by @ydshieh in #29610cache_position update in generate by @gante in #29467generation_config by @gante in #29675filter_models by @ydshieh in #29673glue to nyu-mll/glue by @lhoestq in #29679filter_models" by @ydshieh in #29682filter_models by @ydshieh in #29710bnb] Make unexpected_keys optional by @younesbelkada in #29420gradio.Interface.from_pipeline by @abidlabs in #29684The following contributors have made significant changes to the library over the last release:
🤗 Transformers: the model-definition framework for state-of-the-art machine learning models in text, vision, audio, and multimodal models, for both inference and training.